Research
At the Audio, Music, and AI (AMAAI) Lab at SUTD, our mission is to advance artificial intelligence for music and audio. We design systems that can understand, generate, and interact with music, combining deep learning, signal processing, and music theory. Our research spans creative AI, music information retrieval, multimodal learning, and ethical AI in music.
Text-to-Music Generation
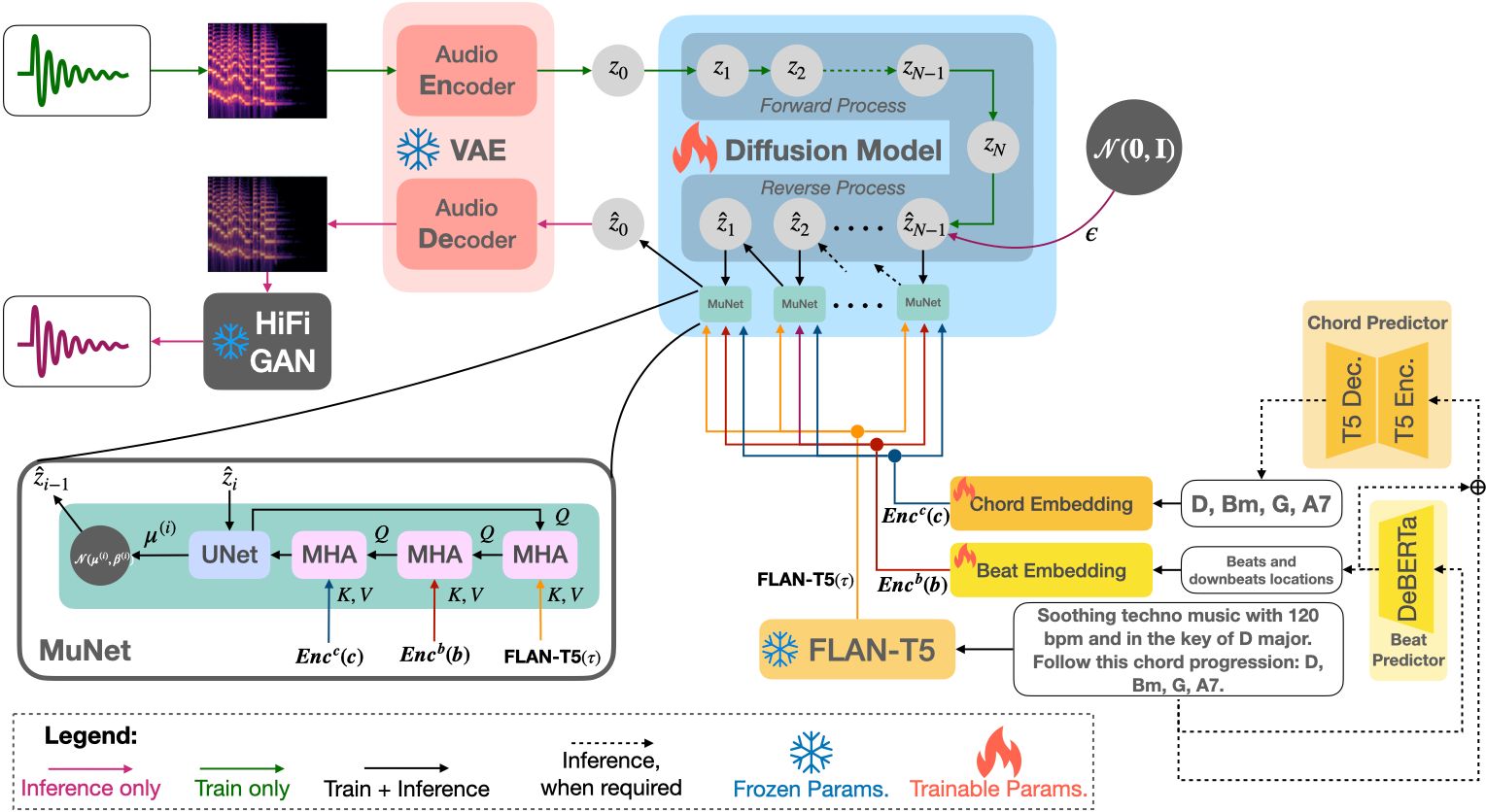
We developed Mustango, a music-domain-knowledge-inspired text-to-music system based on diffusion models. Unlike prior systems that rely only on general text prompts, Mustango enables controllable music generation with rich captions that specify chords, beats, tempo, and key.
Video-to-Music Generation
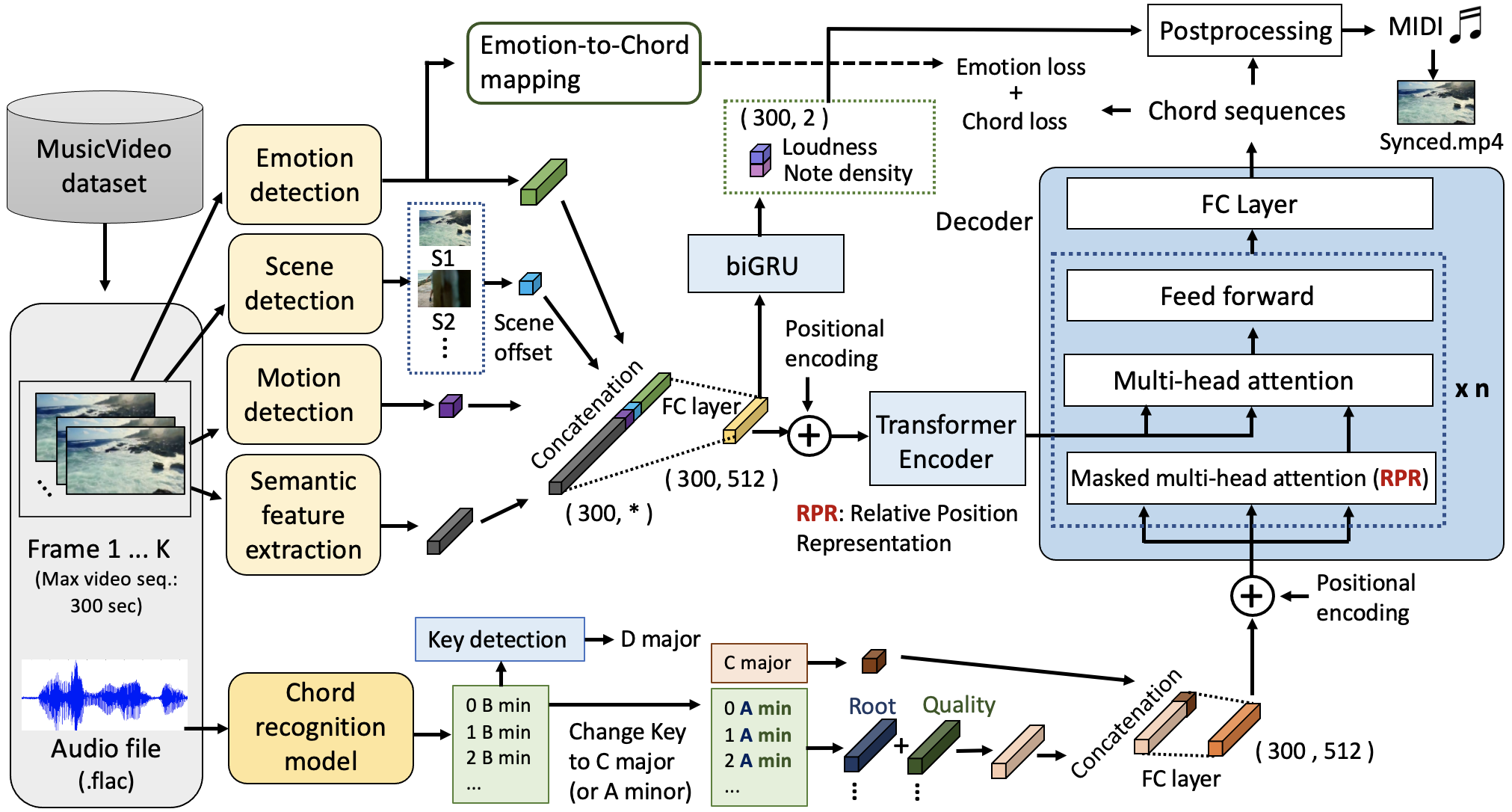
Music often coexists with video and other modalities, yet most generative AI models cannot create music that matches a given video. To address this, we developed Video2Music, a generative framework that produces music conditioned on visual and semantic cues.
Music Emotion Recognition (MER)
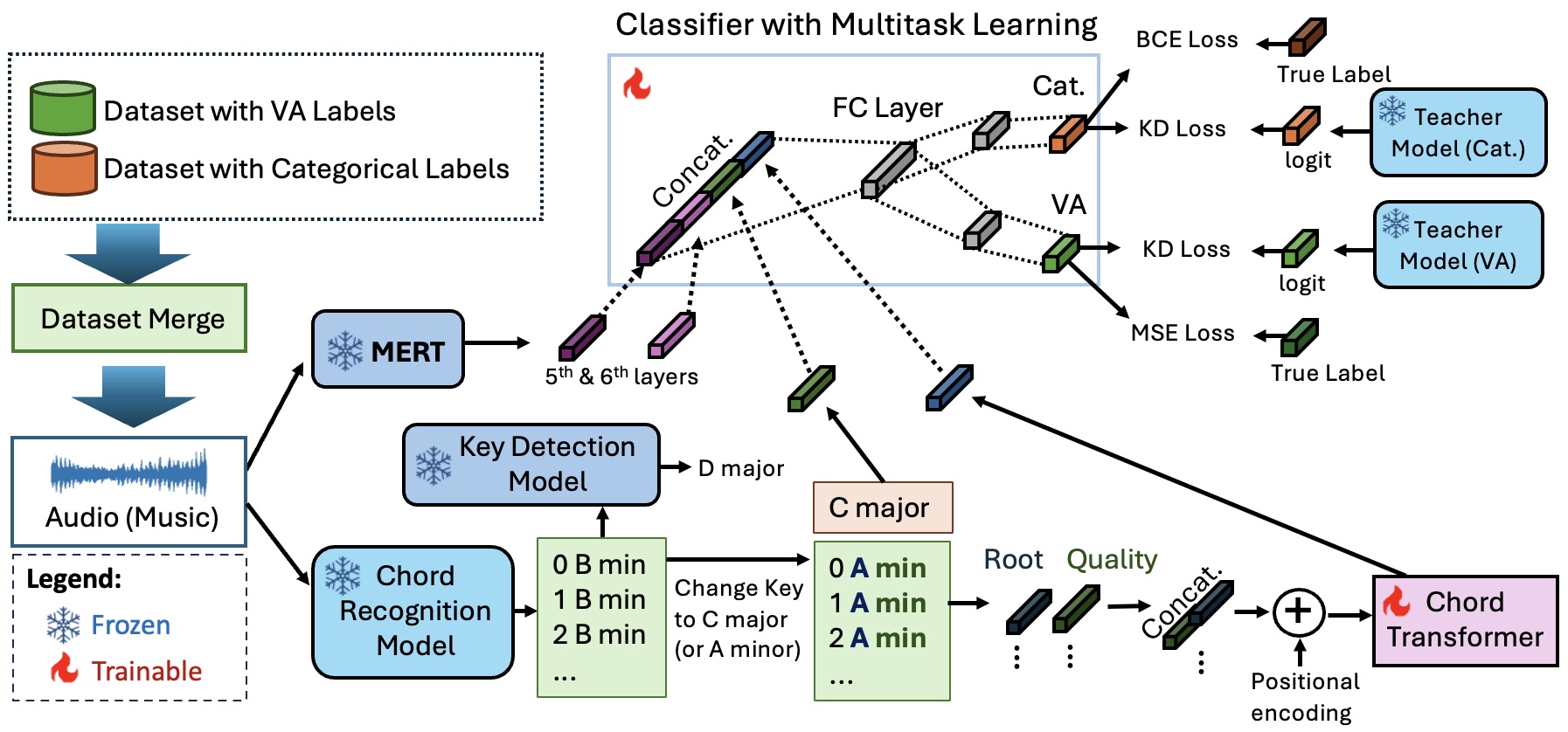
We study how music evokes emotions by unifying categorical (e.g., happy, sad) and dimensional (e.g., valence–arousal) models. Our framework, released as Music2Emo, integrates deep embeddings with music-theory-informed features (e.g., chords, key) and leverages multitask learning to improve generalization across datasets. This work enables richer emotion-aware music recommendation and generation.
Automatic Music Transcription and Analysis
Through models such as DiffRoll and nnAudio, we push the limits of deep learning for transcription and symbolic analysis, including chord recognition, onset detection, and alignment between audio and score.
Creative AI and Plagiarism Detection
With generative AI raising originality concerns, we design systems to detect similarity in melody, harmony, timbre, and lyrics.
Our work supports both creative exploration and intellectual property protection.
Foundational Music Models
We build large-scale joint audio–text embedding models and foundational music models that power downstream tasks such as retrieval, captioning, recommendation, and adaptive generation.
Open-Source Tools and Datasets
We actively contribute to the community with open-source projects such as Mustango, Video2Music, Music FaderNets, DiffRoll, and MidiCaps.
These resources promote reproducibility and fuel innovation in music AI.